I was thinking about writing a smallish blog post summarizing my thoughts on closure variables vs. instance field performance as a reply to Marijn Haverbeke’s post which postulates initial mystery when I realized that this is an ideal candidate for a longer post that illustrates how V8 handles closures and how these design decisions affect performance.
Contexts
If you program JavaScript you probably know that every function carries around a lexical environment that is used to resolve variables into their values when you execute function’s body. This sounds a bit vague but actually boils down to a very simple thing:
function makeF() {
var x = 11;
var y = 22;
return function (what) {
switch (what) {
case "x": return x;
case "y": return y;
}
}
}
var f = makeF();
f("x");Function f needs some kind of storage attached to it to keep variables x and y because when f is called makeFs activation that initially created them no longer exists.
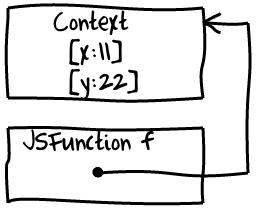
V8 does exactly this: it creates an object called Context and attaches it to the closure (which is internally represented with an instance of JSFunction class).
[From here on I will be saying context variable instead of captured variable.] There are however a couple of important nuances. First of all V8 creates a Context when we enter makeF not when we create a closure itself as many people expect. It is important to keep this in mind when binding variables that are also used in a hot loop. Optimizing compiler will not be able to allocate such variables to registers and each load and store will become a memory operation.
[There is an optimization called register promotion that allows compiler to forward loads to stores across loops and delay storing value into memory for as long as possible but nothing similar is implemented in V8 at the moment]
function foo() {
var sum = 0; // sum is promoted to the Context because it used by a closure below.
for (var i = 0; i < 1000; i++) {
// Here V8 will store sum into memory on every interation.
// This will also cause allocation of a new box (HeapNumber) for
// a floating point value.
sum += Math.sqrt(i);
}
if (baz()) {
setTimeout(function () { alert(sum); }, 1000);
}
}Another thing to keep in mind: if Context is potentially needed it will be created eagerly when you enter the scope and will be shared by all closures created in the scope. If scope itself is nested inside a closure then newly created Context will have a pointer to the parent. This might lead to surprising memory leaks. For example:
function outer() {
var x = HUGE; // huge object
function inner() {
var y = GIANT; // giant object :-)
use(x); // usage of x cause it to be allocated to the context
function innerF() {
use(y); // usage of y causes it to be allocated to the context
}
function innerG() {
/* use nothing */
}
return innerG;
}
return inner();
}
var o = outer(); // o will retain HUGE and GIANT.In this code closure innerG stored in the variable o will retain:
GIANTthrough a link to a sharedContextthat was used byinnerFto access variabley;HUGEthrough a link to a sharedContextthat links to the parentContextcreated forinner.
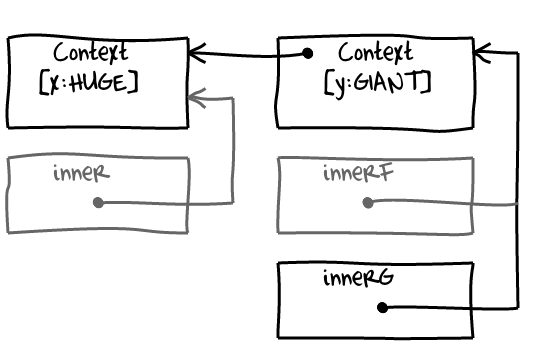
inner itself will survive as long as o points to innerG, because inner is retained by the context it created for innerF and innerG. The same is true for outer (except that outer is also retained through global variable, so there is no leak): context it created for inner points back to it. For the asynchronous code with deeply nested callbacks it might mean that outermost callback will be kept alive until the inner most dies. This will in turn increase the pressure on garbage collection and in the worst case outer callback might even end up being promoted to the old generation. Avoiding deep callback nesting in hot places might improve your app's performance by reducing the pressure on GC.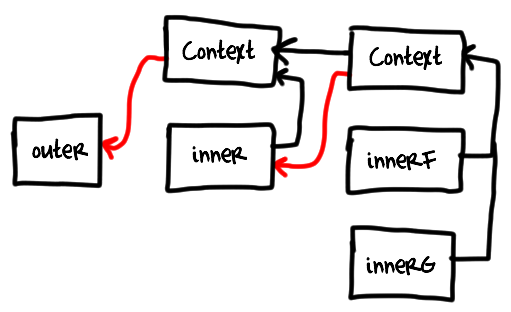
It is useful to keep this picture in mind when debugging memory leaks in callback-centric code bases.
In addition to normal rules governing outer scope references certain language constructs force variables to be context allocated:
- direct call to
evalandwith-statement cause all variables in all scopes enclosing a scope containing them to be context allocated; - reference to
argumentsobject from a non-strict function causes parameters to be context allocated;
function f(a) { // a is context allocated
var x = 10; // x is context allocated
function g(b) { // b is context allocated
var y = 10; // y is context allocated
function h(c) { // c is context allocated
with (obj) {
z = c;
}
}
h(b);
}
g(a);
}
function k(x, y) { // x and y are context allocated
return arguments[0] + arguments[1];
}
function sk(x, y) { // x and y are not context allocated
"use strict";
return arguments[0] * arguments[1];
}From the last observation it also follows that hot functions using arguments object should either have an empty formal parameter list or be declared strict because this allows to avoid allocation and enables inlining (functions that have to allocate a context are not inlined).
Generated code
Now lets take a look at the code that V8 compilers (there are two) generate for reading and writing context variables in comparison to the code generated for a monomorphic instance fields access.
[
To see machine code generated by V8 you can fetch V8's source from the repository, build a standalone shell d8 and invoke it with --print-code --print-code-stubs --code-comments. See cheat sheet below.
∮ svn co http://v8.googlecode.com/svn/branches/bleeding_edge v8
∮ cd v8
∮ make dependencies
∮ make ia32.release objectprint=on disassembler=on
∮ out/ia32.release/d8 --print-code --print-code-stubs --code-comments test.js
]
function ClassicObject() {
this.x = 10;
}
ClassicObject.prototype.getX = function () {
return this.x; // (1)
};
function ClosureObject() {
var x = 10;
return {
getX: function () {
return x; // (2)
}
};
}
var classic_object = new ClassicObject();
var closure_object = new ClosureObject();
// Now lets loop them to force compilation and optimization.
for (var i = 0; i < 1e5; i++) classic_object.getX();
for (var i = 0; i < 1e5; i++) closure_object.getX();Not surprisingly instance field load (1) is compiled by non-optimizing compiler into an inline cache invocation:
mov eax, [ebp+0x8] ;; load this from the stack
mov edx, eax ;; receiver in edx
mov ecx, "x" ;; property name in ecx
call LoadIC_Initialize ;; invoke IC stubAfter it is executed several times IC call gets patched with the following stub:
test_b dl, 0x1 ;; check that receiver is an object not a smi (SMall Integer)
jz miss ;; otherwise fallthrough to miss
cmp [edx-1], 0x2bb0ece1 ;; check hidden class of the object
jnz miss ;; otherwise fallthrough to miss
mov eax, [edx+0xb] ;; inline cache hit, load field by fixed offset and return
ret
miss:
jmp LoadIC_Miss ;; jump to runtime to handle inline cache miss.Nothing unexpected here, it is a classical implementation of an inline caching. If you want to read a highlevel explanation of how inline caches and hidden classes work check out my post with implementation of Inline Cache in JavaScript.
If we take a look at the load of a context variable (2) we will discover that it is compiled even by the nonoptimizing compiler into something much simpler:
mov eax, esi ;; move context to eax
mov eax, [eax + 0x17] ;; load variable from a fixed offset in the context.There are two things to notice here:
- V8 keeps a dedicated register
esifor the current context, to avoid loading it from the frame or closure object itself; - compiler was able to resolve variable into a fixed index during the compilation so there is no late binding, no lookup overhead and no need to involve inline caches.
If we take a look at the optimized code then we discover that loading of a context variable is basically the same, but loading of an instance field from the optimized code is a bit different:
;;; @11: gap.
mov eax,[ebp+0x8]
;;; @12: check-non-smi.
test eax,0x1
jz 0x3080a00a ;; deoptimization bailout 1
;;; @13: gap.
;;; @14: check-maps.
cmp [eax-1],0x2bb0ece1 ;; object: 0x2bb0ece1 <Map(elements=3)>
jnz 0x3080a014 ;; deoptimization bailout 2
;;; @15: gap.
;;; @16: load-named-field.
mov eax,[eax+0xb]
;;; @17: gap.
;;; @18: return.
mov esp,ebp
pop ebp
ret 0x4[Here comments ;;; @N: refer to instructions in Crankshaft's low-level IR aka lithium].
Crankshaft specialized the load site for a particular type of object and inserted type guards that cause deoptimization and a switch to unoptimized code when they fail. One can say that essentially Crankshaft inlined IC stub and decomposed it into individual operations (checking non-sminess, checking hidden class, loading field) and rerouted slow case (miss) through deoptimization. V8 does not actually implement type specialization as inlining of a stub but this is a very handy way of thinking about it especially because the main and only source of type information currently used by V8 is inline caches. [Take a note of this, I’ll discuss some consequences below.]
Splitting guards and actual operations (like loads) allows optimizing compiler to eliminate redundancy. Lets check what happens if we add one more field into our class (I am skipping warm up code):
function ClassicObject() {
this.x = 10;
this.y = 20;
}
ClassicObject.prototype.getSum = function () {
return this.x + this.y;
};Non-optimized version of getSum will have three ICs (one for each property load and one for + which also has a bit of late binding mixed in), but optimized version is more compact than that:
;;; @11: gap.
mov eax,[ebp+0x8]
;;; @12: check-non-smi.
test eax,0x1
jz 0x5950a00a ;; deoptimization bailout 1
;;; @13: gap.
;;; @14: check-maps.
cmp [eax-1],0x24f0ed01 ;; object: 0x24f0ed01 <Map(elements=3)>
jnz 0x5950a014 ;; deoptimization bailout 2
;;; @15: gap.
;;; @16: load-named-field.
mov ecx,[eax+0xb]
;;; @17: gap.
;;; @18: load-named-field.
mov edx,[eax+0xf]Instead of leaving two check-non-smi and two check-maps guards compiler performed common subexpression elimination (CSE) and eliminated redundant guards. Code looks shiny but loads from context look no less shiny and do not require any guards because their binding is resolved statically. How does it happen then that closure based OOP ends up being slower than a classical one?
Lets return to our example and add more OOPness into it (after all OO is about methods calling methods calling methods calling methods…):
function ClassicObject() {
this.x = 10;
this.y = 20;
}
ClassicObject.prototype.getSum = function () {
return this.getX() + this.getY();
};
ClassicObject.prototype.getX = function () { return this.x; };
ClassicObject.prototype.getY = function () { return this.y; };
function ClosureObject() {
var x = 10;
var y = 10;
function getX() { return x; }
function getY() { return y; }
return {
getSum: function () {
return getX() + getY();
}
};
}
var classic_object = new ClassicObject();
var closure_object = new ClosureObject();
for (var i = 0; i < 1e5; i++) classic_object.getSum();
for (var i = 0; i < 1e5; i++) closure_object.getSum();I am not going to look at the non-optimized code now but will immediately proceed to optimized code of function ClassicObject.prototype.getSum
;;; @11: gap.
mov eax,[ebp+0x8]
;;; @12: check-non-smi.
test eax,0x1
jz 0x2b20a00a ;; deoptimization bailout 1
;;; @14: check-maps.
cmp [eax-1],0x5380ed01 ;; object: 0x5380ed01 <Map(elements=3)>
jnz 0x2b20a014 ;; deoptimization bailout 2
;;; @16: check-prototype-maps.
mov ecx,[0x5400a694] ;; global property cell
cmp [ecx-1],0x5380ece1 ;; object: 0x5380ece1 <Map(elements=3)>
jnz 0x2b20a01e ;; deoptimization bailout 3
;;; @18: load-named-field.
mov ecx,[eax+0xb]
;;; @24: load-named-field.
mov edx,[eax+0xf]Looks almost the same as we had before… Wait a second! What happened with all those calls to getX and getY, what is this check-prototype-maps thingy and how did field loads appear directly in getSum code?
The truth is Crankshaft inlined both of these small functions into getSum and completely eliminated calls. Obviously this inlining decision will become incorrect if somebody replaces getX or getY on the ClassicObject.prototype that is why Crankshaft generated a guard against hidden class of the prototype — helpful check-prototype-maps fellow. There is another interesting trick behind this check: V8’s hidden classes encode not only structure of the object (which properties at which offsets object has) but also methods attached to the object (which closure is attached to which property). This allows to make object-oriented programs quite faster, with a single guard verifying several assumptions about the object.
If we now take a look at optimized code attached to the closure_object.getSum then we will become a little bit disappointed:
;;; @12: load-context-slot.
mov ecx,[eax+0x1f] ;; load getX (optimizing compiler placed context in eax here)
;;; @14: global-object.
mov edx,[eax+0x13]
;;; @16: global-receiver.
mov edx,[edx+0x13]
;;; @18: check-function.
cmp ecx,[0x5400a714] ;; global property cell
jnz 0x2b20a00a ;; deoptimization bailout 1
;;; @20: constant-t.
mov ecx,[0x5400a71c] ;; global property cell
;;; @22: load-context-slot.
mov edx,[ecx+0x17] ;; load x
;;; @28: load-context-slot.
mov eax,[eax+0x23] ;; getY
;;; @30: check-function.
cmp eax,[0x5400a724] ;; global property cell
jnz 0x2b20a014 ;; deoptimization bailout 2
;;; @32: constant-t.
mov ecx,[0x5400a72c] ;; global property cell
;;; @34: load-context-slot.
mov eax,[ecx+0x1b] ;; load yOptimizing compiler was able to inline both getX and getY but it did not realize several things:
- even at the parser level it is already obvious that
getXandgetYare immutable constants that are not modified in runtime so there is no need to guard inlined code with a check against closure identity; getX,getYandgetSumhave the same context but optimizer did not take that into account, instead it embedded context ofgetXand context ofgetYas constants into the code introducing unnecessary indirection through cells (instructions@20and@32).
This happens because Crankshaft does not fully utilize static information that parser could give it and instead relies on the type feedback which in fact can be easily lost if you create two ClosureObject objects.
To observe this disaster lets change our warm up code a bit:
var classic_objects = [new ClassicObject(), new ClassicObject()];
var closure_objects = [new ClosureObject(), new ClosureObject()];
for (var i = 0; i < 1e5; i++) classic_objects[i % 2].getSum();
for (var i = 0; i < 1e5; i++) closure_objects[i % 2].getSum();Optimized code in ClassicObject.prototype.getSum did not change at all because hidden classes of both classic objects are the same as they were constructed the same way. However quality of the code in the ClosureObject’s getSum degraded significantly. [Half a year ago V8 would even produce several copies of optimized code one for each getSum closure, but now it pays more attention to sharing optimized code across closures produced from the same function literal]
;;; @12: load-context-slot.
mov edi,[eax+0x1f] ;; edi <- getX
;;; @14: global-object.
mov ecx,[eax+0x13]
;;; @16: global-receiver.
mov ecx,[ecx+0x13]
;;; @17: gap.
mov [ebp+0xec],ecx
;;; @18: push-argument.
push ecx
;;; @19: gap.
mov esi,eax
;;; @20: call-function.
call CallFunctionStub ;; invoke edi (contains getX)
;;; @21: gap.
mov [ebp+0xe8],eax ;; spill x returned from getX
;;; @23: gap.
mov esi,[ebp+0xf0]
;;; @24: load-context-slot.
mov edi,[esi+0x23] ;; edi <- getY
;;; @26: push-argument.
push [ebp+0xec] ;; push this
;;; @28: call-function.
call CallFunctionStub ;; invoke edi (contains getY)Calls to getX and getY are no longer inlined and even more — V8 does not understand that they are guaranteed to be functions — they are not direct and go through a generic CallFunctionStub that will check if the target (passed in register edi) is actually a function.
Why did this happen? The short answer: type feedback from two instances of getSum got mixed up together turning getX and getY call sites into megamorphic calls. The easiest way to explain it is to draw a picture:
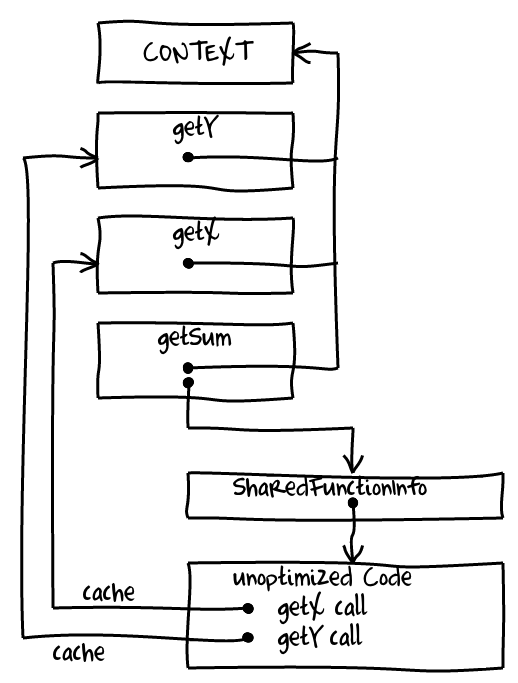
V8 shares unoptimized code across all closures produced from the same function literal. At the same time inline caches and other facilities collecting type feedback are attached to unoptimized code. As the result type feedback is shared and mixed. Everything is mostly fine while type feedback is based on hidden classes because they capture organization of objects — objects constructed the same way have the same hidden class. However for getX and getY callsites V8 collects call targets. If you have only one ClosureObject with a single getSum everything will seem monomorphic to V8 because getX and getY are always the same. However if you create and start using another ClosureObject those callsites will become megamorphic: identity of call targets does not match anymore.
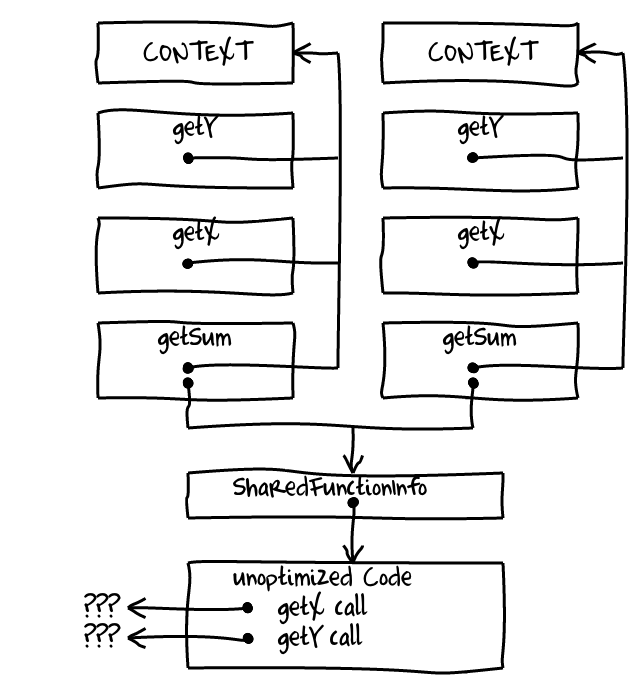
There are multiple things that V8 could do better here like utilizing static information about immutability of bindings that parser can recover from the source and using SharedFunctionInfo identity instead of closure identity for call target feedback and inlining guards (Issue 2206).
Until these issues are addressed classical objects might be a better choice if you are looking for a predictable performance. Though each individual case requires careful investigation (e.g. is it singleton or multiple objects are going to be produced? is it on hot path? etc). And of course don’t optimize before you need to optimize :-)
Want to discuss
contents of this post? Drop me a mail [email protected] or find me on
Mastodon,
X or Bluesky.