dart:mirrors
might be the most misunderstood, mistreated, neglected component of the Dart’s
core libraries. It has been a part of Dart language since the very beginning and
is still surrounded by the fog of uncertainty and marked as Status: Unstable
in the documentation - even though APIs have not changed for a very long time.
dart:mirrors rarely hits spotlight because it is a library that enables
metaprogramming and as such an average Dart user rarely has to deal with it
directly - instead it is something framework/library authors have to deal with.
Indeed my journey towards this post did not actually start with dart:mirrors,
instead it started with something completely different:
JSON deserialization
In December 2016 I was hanging out on Dart’s Slack channel (now defunct in favor
of dart-lang Gitter) and saw a user, let
us call him Maximilian, inquiring about the ways to parse JSON in Dart. If you
are coming from JavaScript then this sort of question might surprise you: isn’t
parsing JSON in Dart as easy as doing JSON.parse(...) in JavaScript?
Yes, it is as easy: you can simply use JSON.decode(...) from the built in
dart:convert library, however there is a catch. JavaScript’s JSON.parse can
give you back an object because JavaScript objects are shapeless clouds of
properties and code like this is totally fine:
let userData = JSON.parse(str);
console.log(`Got user ${userData.name} from ${userData.city}`);However each Dart object has a fixed class which completely determines its
shape. Dart’s JSON.decode can given you back a Map but it can’t give you
back an object of your custom type:
Map userData = JSON.decode(str);
console.log("Got user ${userData['name']} from ${userData['city']}"); // OK
class UserData {
String name;
String city;
}
UserData userData = JSON.decode(str); // NOT OK
console.log("Got user ${userData.name} from ${userData.city}");One common solution to this problem is to write marshaling helpers that can
create your objects from Maps:
class UserData {
String name;
String city;
UserData(this.name, this.city);
UserDate.fromJson(Map m)
: this(m['name'], m['city']);
}
UserData userData = new UserDate.fromJson(JSON.decode(str));
console.log("Got user ${userData.name} from ${userData.city}");But writing this sort of boilerplate code is rarely a welcomed way to spend
the day. That’s why pub contains plenty of packages
that automate this and…
drumroll… some of them
use dart:mirrors.
What is dart:mirrors?
If you are not a language person chances are that you have never heard the term mirror in connection with programming languages. It is a play of the words: mirror API allows program to reflect upon itself. Historically it originates from SELF, like a lot of other great VM technology. Check out Gilad Bracha’s post and follow the links if you want to learn more about mirrors and their role in other systems.
Mirrors exist to answer reflective questions like: «What is the type of the given object?», «What fields/methods does it have?», «What is the type of field?», «What is the type of a parameter to the given method?» and to execute reflective actions like «Get the value of this field from that object!» and «Invoke this method on that object!».
In JavaScript objects themselves posses reflective capabilities: to dynamically
get a property by name you can just do obj[key] to invoke a method by its name
with a dynamic list of arguments obj[name].apply(obj, args).
Dart on the other hand encapsulates these capabilities within dart:mirrors
library:
import 'dart:mirrors' as mirrors;
setField(obj, name, value) {
// Get an InstanceMirror that allows to access obj state
final mirror = mirrors.reflect(obj);
// Set the field through the mirror.
mirror.setField(new Symbol(name), value);
}The API might seem a bit wordy on the first glance, but in reality things like
new Symbol(name) are there for a reason: they remind you that names given to
classes, methods and fields are not there to stay - they might be changed,
mangled by the compiler in attempt to reduce the size of the generated code.
Keep this in mind we will return to this later.
Back to JSON deserialization
Deserialization libraries based on dart:mirrors are usually extremely easy to
use: you just put an annotation on your classes and you are set. Here is for
example how data model from original Slack question by Maximilian looks like
with dartson annotations:
[I renamed all the fields and classes to anonymize it. The structure of the data model is retained.]
import 'package:dartson/dartson.dart';
@Entity()
class Data {
String something0;
String something1;
List<Data1> sublist0;
List<Data2> sublist1;
List<Data3> sublist2;
}
@Entity()
class Data1 {
String something0;
String something1;
String something2;
String something3;
String something4;
String something5;
String something6;
}
@Entity()
class Data2 {
String something0;
String something1;
}
@Entity()
class Data3 {
String something0;
String something1;
}
final DSON = new Dartson.JSON();
// Deserialize Data object from a JSON encoded string.
Data d = DSON.decode(string, new Data());Somebody might ask: if things are this simple and smooth what’s the question then?
It turns out dartson is really-really slow. When Maximilian took a 9Mb data
file containing the data he needed to work with he saw the following:
$ dart decode-benchmark.dart --with-dartson loaded data.json: 9389696 bytes DSON.decode(...) took: 2654ms $ d8 decode-benchmark.js loaded data.json: 9389696 bytes JSON.parse(...) took: 118ms
These numbers don’t look that great. Lets do a few more measurements:
$ dart decode-benchmark.dart --with-json loaded data.json: 9389696 bytes JSON.decode(...) took: 236ms
So just decoding JSON string into unstructured forest of Maps and Lists is
10x faster than using dartson? That is rather disheartening and dart:mirrors
are obviously to blame here! At least that’s what Slack channel consensus on
this issue was.
Before we dig a little bit deeper, I would like to make one observation here:
V8’s JSON parser is written in C++, Dart’s is actually written in Dart and it is a streaming parser. 2x difference
between Dart’s JSON.decode(...) and V8 JSON.parse(...) does not look that
bad when you realize this.
Another interesting thing here is to try and benchmark some other language that
uses reflection to deserialize JSON: Maximilian tried Go’s encoding/json
package:
import (
"io/ioutil"
"encoding/json"
"fmt"
"time"
)
type Data struct {
Something0 string `json:"something0"`
Something1 string `json:"something1"`
Sublist0 []Data1 `json:"sublist0"`
Sublist1 []Data2 `json:"sublist1"`
Sublist2 []Data3 `json:"sublist2"`
}
var data Data
err := json.Unmarshal(data, &data)$ go run decode-benchmark.go loaded data.json: 9389696 bytes json.Unmarshal(...) took: 279ms
So in Go deserializing JSON into a structure takes rougly the same time as in
Dart it takes to deserialize JSON into an unstructured Maps even though
encoding/json does use reflection to do it.
Here is a boxplot of times it takes to parse the same 9MB input file from Maximilian (30 runs within the same process):
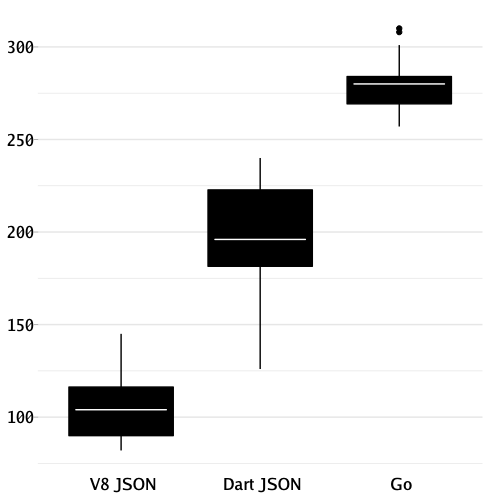
dartson is absent from the picture because it is at least 10x slower than
anything else…
Digging into dartson performance
As always one of the easiest ways to investigate performance of Dart code is to use Observatory:
$ dart --observe decode-benchmark.dart --dartson Observatory listening on http://127.0.0.1:8181/ loaded data.json: 9389696 bytes ...
Looking at the CPU profile page in the observatory reveals disturbing picture:
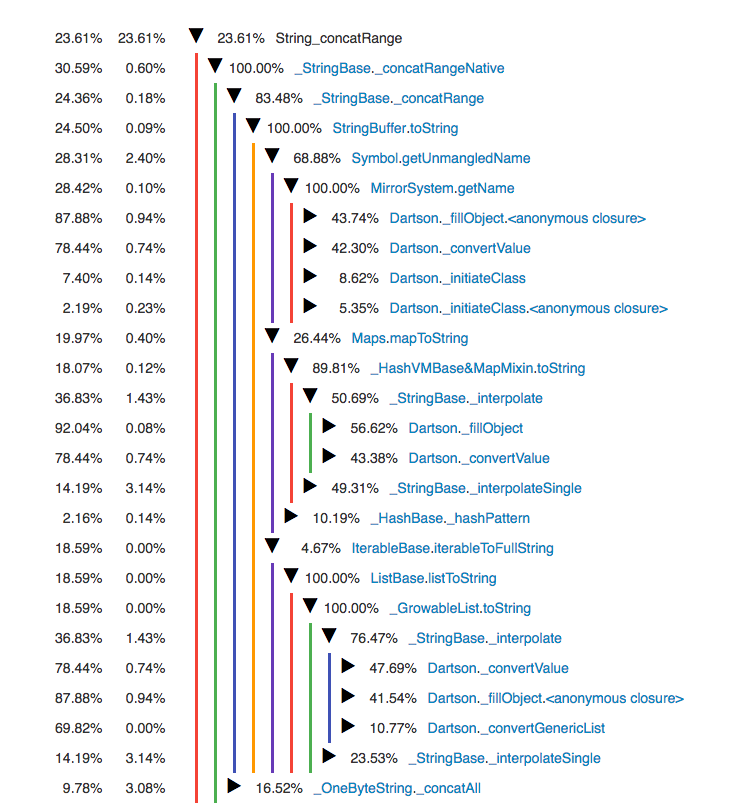
This picture tells us that dartson is spending really large amount of time
interpolating strings. A quick look at the source code
reveals that dartson does a lot of logging like this:
void _fillObject(InstanceMirror objMirror, Map filler) {
// ...
_log.fine("Filled object completly: ${filler}");
}and like this
Object _convertValue(TypeMirror valueType, Object value, String key) {
// ...
_log.finer('Convert "${key}": $value to ${symbolName}');
// ...
}This is obviously a lot of wasted time because string interpolation is performed even when logging is disabled. Thus the first step towards more performant deserialization would be to completely remove all this logging:
$ dart decode-benchmark.dart --with-dartson loaded data.json: 9389696 bytes DSON.decode(...) took: 1542ms
Voilà! We just made JSON deserialization with dartson 42% faster by
changing something that has nothing to do with either mirrors or JSON. If we
look at the profile again then we discover that things are finally starting to
get interesting:

Here we seem to repeatedly requesting mirror to compute metadata associated
with some declaration. Lets look into Dartson._fillObject:
void _fillObject(InstanceMirror objMirror, Map filler) {
ClassMirror classMirror = objMirror.type;
classMirror.declarations.forEach((sym, decl) {
// Look at the declaration (e.g. a field) and make a decision
// how to deserialize it from the given [filler] based on
// the metadata associated with it and field's type.
});
}Whenever I face an optimization problem the first question I always ask myself
is «Does this code repeats some operation? Can it be cached?».
For Dartson._fillObject answers are Yes and Yes. The code above repeatedly
walks through all declarations in the given class and makes the very same
decisions again and again. These decisions can be cached because classes in Dart
don’t change dynamically - they don’t get new fields, nor fields change their
declared type. Lets restructure the code:
// For each class this cache contains a list of deserialization actions:
// "take a value from JSON map, convert it and store it in the given field".
// Actions are stored as triplets linearly in the list:
//
// [jsonName_0, fieldName_0, convertion_0,
// jsonName_1, fieldName_1, convertion_1,
// ...]
//
final Map<ClassMirror, List> fillActionsCache = <ClassMirror, List>{};
/// Puts the data of the [filler] into the object in [objMirror]
/// Throws [IncorrectTypeTransform] if json data types doesn't match.
void _fillObject(InstanceMirror objMirror, Map filler) {
ClassMirror classMirror = objMirror.type;
var actions = fillActionsCache[classMirror];
if (actions == null) {
// We did not hit the cache and we need to compute a list of actions.
}
// Iterate all actions and execute those that have a matching field
// in the [filler].
for (var i = 0; i < actions.length; i += 3) {
final jsonName = actions[i];
final value = filler[jsonName];
if (value != null) {
final fieldName = actions[i + 1];
final convert = actions[i + 2];
objMirror.setField(fieldName, convert(jsonName, value));
}
}
}Notice that we separately cache source jsonName and target fieldName
(as a Symbol) because field names don’t necessary match source JSON property
names as dartson supports renamings via @Property(name: ...) annotation.
Another thing here is that we cache type conversions as a closure to avoid
repeatedly looking up field’s type and figuring out which conversion to apply.
When we enter _fillObject for the first time with some class we need to
compute a list of deserialization actions for this class. Essentially it’s the
same code that used to perform deserialization but instead of populating an
actual object we now populate a list of actions to perform:
actions = [];
classMirror.declarations.forEach((Symbol fieldName, decl) {
// We are only interested in public non-constant fields and setters.
if (!decl.isPrivate &&
((decl is VariableMirror && !decl.isFinal && !decl.isConst) ||
(decl is MethodMirror && decl.isSetter))) {
String jsonName = _getName(fieldName);
TypeMirror valueType;
if (decl is MethodMirror) { // Setter.
// Setters are called `name=`. Remove trailing `=`.
jsonName = jsonName.substring(0, jsonName.length - 1);
valueType = decl.parameters[0].type;
} else { // Field.
valueType = decl.type;
}
// Check if the property was renamed via @Property(name: ...)
final Property prop = _getProperty(decl);
if (prop?.name != null) {
jsonName = prop.name;
}
// Populate actions.
actions.add(jsonName);
actions.add(fieldName);
actions.add(_valueConverter(valueType));
}
});
// No more actions will be added so convert actions list to non-growable array
// to reduce amount of indirections.
fillActionsCache[classMirror] = actions = actions.toList(growable: false);In addition to this code we also have to rewrite Dartson._convertValue.
In original dartson this function takes TypeMirror and a value to convert
and returns converted value:
Object _convertValue(TypeMirror valueType, Object value, String key) {
if (valueType is ClassMirror &&
!valueType.isOriginalDeclaration &&
valueType.hasReflectedType &&
!_hasOnlySimpleTypeArguments(valueType)) {
ClassMirror classMirror = valueType;
// handle generic lists
if (classMirror.originalDeclaration.qualifiedName == _QN_LIST) {
return _convertGenericList(classMirror, value);
} else if (classMirror.originalDeclaration.qualifiedName == _QN_MAP) {
// handle generic maps
return _convertGenericMap(classMirror, value);
}
} // else if (...) {
// ... various types handled here ...
return value;
}We follow the same idea as we applied to _fillObject, instead of performing
conversion we compute how to perform the conversion:
// Function that converts a [value] read from the JSON property to expected
// type.
typedef Object ValueConverter(String jsonName, Object value);
// Compute [ValueConverter] based on the property of the field where the
// the value taken from JSON map will be stored.
ValueConverter _valueConverter(TypeMirror valueType) {
if (valueType is ClassMirror &&
!valueType.isOriginalDeclaration &&
valueType.hasReflectedType &&
!_hasOnlySimpleTypeArguments(valueType)) {
ClassMirror classMirror = valueType;
// handle generic lists
if (classMirror.originalDeclaration.qualifiedName == _QN_LIST) {
return (jsonName, value) => _convertGenericList(classMirror, value); // ⚠
} else if (classMirror.originalDeclaration.qualifiedName == _QN_MAP) {
// handle generic maps
return (jsonName, value) => _convertGenericMap(classMirror, value); // ⚠
}
} // else if (...) {
// ... various types handled here ...
// Identity convertion.
return (jsonName, value) => value; // ⚠
}With this optimizations dartson reaches new performance heights:
$ dart decode-benchmark.dart --with-dartson loaded data.json: 9389696 bytes DSON.decode(...) took: 488ms
This is 82% faster than its original performance - with this we are finally starting to approach numbers we are seeing from Go.
Can we push it further? Of course! Reading through the code and profiling
reveals few more obvious places where we could avoid repetetive reflective
overheads by applying the same optimization pattern we did before (use
reflection to compute what to do, instead of doing it). For example,
_convertGenericList contains the following code:
List _convertGenericList(ClassMirror listMirror, List fillerList) {
ClassMirror itemMirror = listMirror.typeArguments[0];
InstanceMirror resultList = _initiateClass(listMirror);
fillerList.forEach((item) {
(resultList.reflectee as List)
.add(_convertValue(itemMirror, item, "@LIST_ITEM"));
});
return resultList.reflectee;
}
There are multiple issues with this code:
- adding items to the list one by one, causing growth and relocation - even though list is know ahead of time;
- repetitively figuring out through reflection how to convert each individual
item;
The code can be easily rewritten using our _valueConverter helper:
List _convertGenericList(ClassMirror listMirror, List fillerList) {
ClassMirror itemMirror = listMirror.typeArguments[0];
InstanceMirror resultList = _initiateClass(listMirror);
final List result = resultList.reflectee as List;
// Compute how to convert list items based on itemMirror *once*
// outside of the loop.
final convert = _valueConverter(itemMirror);
// Presize the list.
result.length = fillerList.length;
for (var i = 0; i < fillerList.length; i++) {
result[i] = convert("@LIST_ITEM", fillerList[i]);
}
return result;
}
Another small optimization that could be done in the dartson code is caching
class initiators and moving away from:
// code from _valueConverter handling conversion from Map
// to object.
return (key, value) {
var obj = _initiateClass(valueType);
// ...
// fill obj from value
// ...
return obj.reflectee;
};
to
final init = _classInitiator(valueType);
return (key, value) {
var obj = init();
// ...
// fill obj from value
// ...
return obj.reflectee;
};
It is again exactly the same pattern we applied before so I will not bother you with implementation details.
$ dart decode-benchmark.dart --with-dartson loaded data.json: 9389696 bytes DSON.decode(...) took: 304ms
We have now made dartson 89% faster than its original performance! Furthermore it turns out that warmed up performance of this code is actually rivaling that of Go:

Can we push performance further? Certainly! If we look at our deserialization
chain: from String to Map to an actual forest of objects then the very
first step stands out as redundant. We seem to be allocating Map just
to fill an actual object from it. Can we parse string directly into an object?
If we look closely at Dart VM sources for its JSON parser
we will discover that it is split into two pieces: the actual parser
which walks the input (a single String or a sequence of chunks arriving
asynchronously) and sends events like beginObject, beginArray to the listener which constructs the objects. Unfortunately both _ChunkedJsonParser and listener interface _JsonListener are hidden within dart:convert and user code can’t use them.
At least before we apply this small patch:
diff --git a/runtime/lib/convert_patch.dart b/runtime/lib/convert_patch.dart
index 9606568e0e..0ceae279f5 100644
--- a/runtime/lib/convert_patch.dart
+++ b/runtime/lib/convert_patch.dart
@@ -21,6 +21,15 @@ import "dart:_internal" show POWERS_OF_TEN;
return listener.result;
}
+parseJsonWithListener(String json, JsonListener listener) {
+ var parser = new _JsonStringParser(listener);
+ parser.chunk = json;
+ parser.chunkEnd = json.length;
+ parser.parse(0);
+ parser.close();
+ return listener.result;
+}
+
@patch class Utf8Decoder {
@patch
Converter<List<int>, T> fuse<T>(
@@ -67,7 +76,7 @@ class _JsonUtf8Decoder extends Converter<List<int>, Object> {
/**
* Listener for parsing events from [_ChunkedJsonParser].
*/
-abstract class _JsonListener {
+abstract class JsonListener {
void handleString(String value) {}
void handleNumber(num value) {}
void handleBool(bool value) {}
With JsonListener and parseJsonWithListener exposed from dart:convert we
can build our own JsonListener that does not create any intermediate maps but
instead fills actual objects as parser walks the string.
I have quickly prototyped such parser and while I am not going to walk you through each single line of the code, I am going to highlight some of my design decisions. Full code available in this gist.
Converting Type into auxiliary data-structures once ahead of time
/// Deserialization descriptor built from a [Type] or a [mirrors.TypeMirror].
/// Describes how to instantiate an object and how to fill it with properties.
class TypeDesc {
/// Tag describing what kind of object this is: expected to be
/// either [tagArray] or [tagObject]. Other tags ([tagString], [tagNumber],
/// [tagBoolean]) are not used for [TypeDesc]s.
final int tag;
/// Constructor closure for this object.
final Constructor ctor;
/// Either map from property names to property descriptors for objects or
/// element [TypeDesc] for lists.
final /* Map<String, Property> | TypeDesc */ properties;
}
/// Deserialization descriptor built from a [mirrors.VariableMirror].
/// Describes what kind of value is expected for this property and how
/// how to store it in the object.
class Property {
/// Either [TypeDesc] if the property is a [List] or an object or
/// [tagString], [tagBool], [tagNumber] if the property has primitive type.
final /* int | TypeDesc */ desc;
/// Setter callback.
final Setter assign;
Property(this.desc, this.assign);
}
As our work on dartson showed it pays off to only use mirrors once to build
auxiliary data structures describing deserialization actions in some form.
In my mirror based deserializer I follow the same route, but instead of doing it lazily I do it eagerly and cache the result.
Dynamically adapting to the order of properties in JSON
One interesting observation that can be made by looking at JSON is that properties for objects of the same type are usually arriving in the same order.
This means that we could take a page from V8’s playbook and adapt to this order
dynamically to avoid doing dictionary lookup in TypeDesc.properties for each
new property.
The way I implemented this in the prototype is very straightforward - I simply
record properties in order for the first object with the given TypeDesc and
then attempt to follow the recorded trail. This approach works well for our
sample JSON but might be too naive for the real world full or optional
properties.
class TypeDesc {
/// Mode determining whether this [TypeDesc] is trying to adapt to
/// a particular order of properties in the incoming JSON:
/// the expectation here is that if JSON contains several serialized objects
/// of the same type they will all have the same order of properties inside.
int mode = modeAdapt;
/// A sequence of triplets (property name, hydrate callback, assign callback)
/// recorded while trying to adapt to the property order in the incoming JSON.
/// If [mode] is set to [modeFollow] then [HydratingListener] will attempt
/// to follow the trail.
List<dynamic> propertyTrail = [];
}
class HydratingListener extends JsonListener {
@override
void propertyName() {
if (desc.mode == TypeDesc.modeNone || desc.mode == TypeDesc.modeAdapt) {
// This is either the first time we encountered an object with such
// [TypeDesc], which means we are currently recording the [propertyTrail]
// or we have already failed to follow the [propertyTrail] and have fallen
// back to simple dictionary based property lookups.
final p = desc.properties[value];
if (p == null) {
throw "Unexpected property ${name}, only expect: ${desc.properties.keys
.join(', ')}";
}
if (desc.mode == TypeDesc.modeAdapt) {
desc.propertyTrail.add(value);
desc.propertyTrail.add(p.desc);
desc.propertyTrail.add(p.assign);
}
prop = p;
expect(p.desc);
} else {
// We are trying to follow the trail.
final name = desc.propertyTrail[prop++];
if (name != value) {
// We failed to follow the trail. Fall back to the simple dictionary
// based lookup.
desc.mode = TypeDesc.modeNone;
desc.propertyTrail = null;
return propertyName();
}
// We are still on the trail.
final propDesc = desc.propertyTrail[prop++];
expect(propDesc);
}
}
}
Dynamically generated setter closures
Even though we mostly avoid using mirrors during parsing, we are still forced to use them to set fields when filling objects:
final Setter setField = (InstanceMirror obj, dynamic value) {
obj.setField(fieldNameSym, value);
};
If we look into Dart VM sources we discover
that it used dynamic code generation to speedup InstanceMirror.setField: it
generates and caches small closures of form (x, v) => x.$fieldName = v and
uses them to assign fields instead of going through generic runtime path.
There is an obvious optimization opportunity here: instead of defining
setField as closure that calls InstanceMirror.setField which would in turn
lookup another closure and invoke it to set the field, we want to define
setField to be that very closure which sets the field directly.
There are two ways to achieve that:
- Massage Dart VM’s optimizing compiler to teach it how to specialize
InstanceMirror.setFieldcall-sites when the first parameter is either a constant or a pseudo-constant i.e. an immutable captured variable. This is a very complicated path. - Apply a small patch to Dart VM’s sources to expose dynamic code evaluation capabilities:
diff --git a/runtime/lib/mirrors_impl.dart b/runtime/lib/mirrors_impl.dart
index ec4ac55147..a61baa3e3c 100644
--- a/runtime/lib/mirrors_impl.dart
+++ b/runtime/lib/mirrors_impl.dart
@@ -393,6 +393,8 @@ abstract class _LocalObjectMirror extends _LocalMirror implements ObjectMirror {
}
}
+$evaluate(String expression) => _LocalInstanceMirror._eval(expression, null);
+
class _LocalInstanceMirror extends _LocalObjectMirror
implements InstanceMirror {
and use these capabilities to rewrite our setField
final setField = mirrors.$evaluate('''(obj, value) {
obj.reflectee.${fieldNameStr} = value;
}''');
Results
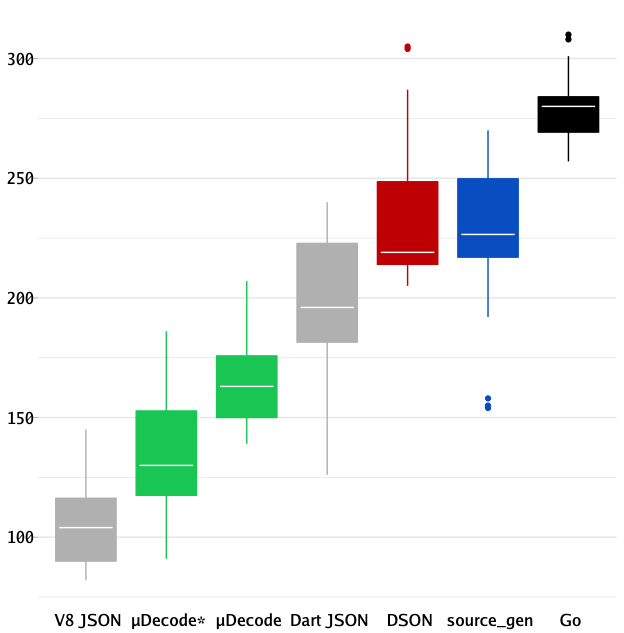
Our prototype labeled μDecode and μDecode* on the plot written in Dart and
using mirrors is doing respectably well against the competition and is
approaching the performance of hand-tuned C++ parser used by V8.
The only difference between μDecode and μDecode* is that μDecode* is using
mirrors.$evaluate to generate field setter closures, while μDecode is
sticking to public dart:mirrors API.
You might notice that this plot also mentions a new player source_gen, which
we did not encounter before.
The problem with mirrors
I hopefully managed to demonstrate that mirrors perform well within JIT compiled environment provided by the Dart VM. Unfortunately the picture would not be complete if I did not cover how mirrors perform in the AOT compiled environments.
Currently Dart has to ahead-of-time compiled targets:
dart2jsis an AOT compiler targeting browser environment by compiling Dart to JavaScript;dart_boostrapis a VM based AOT compiler targeting native code.
The picture with mirrors here is really dire - VM’s AOT configuration currently
does not support dart:mirrors at all, while dart2js supports it only
partially and prints an angry warning whenever you compile an application
importing dart:mirrors.
The reason why AOT compiler shy away from dart:mirrors is its unrestricted
reflective power which allows you to explore, modify and
dynamically invoke anything you can reach transitively. AOT compilers usually
operate under the closed-world assumption that allows them to determine with
varying degree of precision instances of which classes are potentially
allocated, which methods are potentially called (and which are certainly not
called), and even what are the values reaching a particular field. Reflective
capabilities of dart:mirrors significantly complicate and degrade the quality
of global data flow and control flow analyses. Thus AOT compilers have a choice:
- Decline to implement
dart:mirrors- this is what VM have chosen to do; - Make analyses conservative when
dart:mirrorsis used - this is whatdart2jschose to do; - implement more sophisticated control and data flow analyses that can cope with some reflective capabilities;
- fix
dart:mirrorsAPIs to be more declarative to aid AOT compilation.
We will get back to the last option later, but lets first look at where current
dart2js’s choice gets us. If we compile our benchmark to JavaScript via dart2js
and run it in a relatively new V8 we will see results like this:
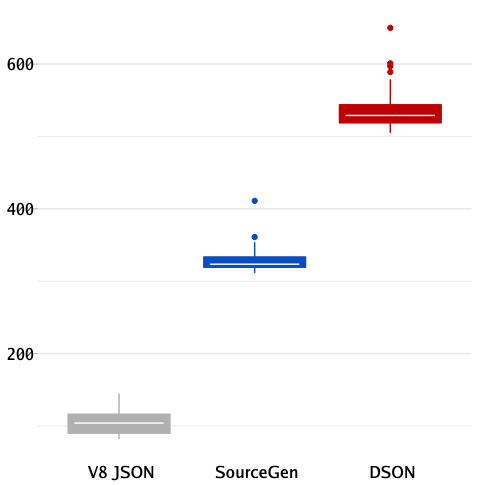
[Note: dartson comes with a transformer which erases
dart:mirrors usage but I am intentionally not using it here because I want to
measure overhead of dart:mirrors]
We can clearly see that we are taking at least 4x penalty for using mirrors
against the baseline: dart2js output is using JSON.parse so it makes total
sense to use V8 JSON as a baseline when trying to establish the amount of
overhead that our abstractions are adding on top of native JSON parser.
Additionally importing dart:mirrors completely disables tree-shaker so the
output contains all the code from all the libraries imported
transitively - most of this code will never be used by the application itself,
but dart2js has to conservatively assume that it can be potentially reached
through mirrors.
Web developers obviously want smaller and faster JavaScript output so libraries
like source_gen sprung into
existence.
[Before source_gen there were pub-transformers,
but because Dart ecosystem is moving away from them I am not going to go into details here. The main difference between transformers and source_gen is
that source_gen generates files on disk that you are supposed to carry around and even commit into your repo, while transformers operated in-memory as
part of the pub-pipeline, making them invisible for tools that were not integrated with pub. Transformers were very powerful
but unwieldy which lead to their demise. In general you don’t want to do expensive global transformations, and especially you don’t want to do them in
memory. What you really want is modular transformations with cachable intermediate results for faster incremental builds.]
Instead of abstracting away boilerplate code using reflective
capabilities, you write a tool that generates boilerplate for you. For example,
if you write in file called decode.dart:
import 'package:source_gen/generators/json_serializable.dart';
part 'decode.g.dart';
@JsonSerializable()
class Data extends Object with _$DataSerializerMixin {
final String something0;
final List<Data1> sublist0;
final List<Data2> sublist1;
final String something1;
final List<Data3> sublist2;
Data(this.something0, this.sublist0, this.sublist1, this.something1, this.sublist2);
factory Data.fromJson(json) => _$DataFromJson(json);
}
then you run source_gen and you get a file decode.g.dart which contains all
the serialization/deserializaton boilerplate:
// GENERATED CODE - DO NOT MODIFY BY HAND
part of mirrors.src.source_gen.decode;
// **************************************************************************
// Generator: JsonSerializableGenerator
// Target: class Data
// **************************************************************************
Data _$DataFromJson(Map json) => new Data(
json['something0'] as String,
(json['sublist0'] as List)
?.map((v0) => v0 == null ? null : new Data1.fromJson(v0))
?.toList(),
(json['sublist1'] as List)
?.map((v0) => v0 == null ? null : new Data2.fromJson(v0))
?.toList(),
json['something1'] as String,
(json['sublist2'] as List)
?.map((v0) => v0 == null ? null : new Data3.fromJson(v0))
?.toList());
abstract class _$DataSerializerMixin {
String get something0;
List get sublist0;
List get sublist1;
String get something1;
List get sublist2;
Map<String, dynamic> toJson() => <String, dynamic>{
'something0': something0,
'sublist0': sublist0,
'sublist1': sublist1,
'something1': something1,
'sublist2': sublist2
};
}
This looks pretty awful (and still not completely free of boilerplate), but it works. Resulting code is fully visible to the AOT compiler and uses no mirrors - so compiler does as good of a job as it would do if you would write the same boilerplate by hand - resulting in smaller and faster JavaScript outputs.
For comparison, JavaScript output for source_gen based benchmark is 12x
smaller and 2x faster than dartson-mirror-based one.
However source_gen based solution:
- it still around 2x slower than native baseline;
- looks very unpleasant to the eye;
Why is it slower?
The main reason for it being slower is that we still allocated intermediate
results: instead of going directly String to object, we first invoke
dart:convert.JSON.decode to produce a forest of Map and List objects,
which we then convert into actual “typed” objects.
If we look under the hood of dart:convert implementation
provided by dart2js, then we discover that things are even more convoluted because native JSON.parse returns a JS object which is not compatible with
Dart’s Map we need to turn it into something that has an interface compatible
with Map:
- If we parse JSON without a reviver then we simply wrap JS object
returned from native
JSON.parseinto_JsonMapclass which implementsMap<String, dynamic>. This wrapper acts like a proper DartMapand makes sure to lazily wrap or convert any nested objects when user accesses them viaMap.operator[]for the first time - preventing escape of “raw” JS objects into the Dart world which does not know how to deal with them. Nested objects (at least those that are not arrays) are converted in the same lazy fashion by wrapping them into_JsonMap. - If we parse JSON
with a reviver then we eagerly convert the output of
JSON.parseinto Dart’sMaps andLists.
All these indirections and lazy data marshaling between three worlds (JavaScript
⇒ Dart Map ⇒ Dart class instances) comes at a cost and to be honest
it is unclear if there are really easy ways to improve it. The overheads of lazy
marshalling can be shaved away by passing an empty reviver into JSON.decode
which makes new Data.fromJson(JSON.decode(str, reviver: _empty)) up to 10% faster than
new Data.fromJson(JSON.decode(str)), but multiple copying still remains a
problem.
[Thanks to Brian Slesinsky for pointing out a trick with empty reviver]
One thing though is clear - dart2js could probably have come with a first class
support for JSON, in a form of special annotations similar @JsonSerializable.
Then it could implement support for JSON serialization/deserialization with
minimal copying (e.g. by lazily patching prototypes of objects returned by
native JSON.parse).
How to make it prettier?
While dart2js could have implemented first class support for JSON, it is just
one of many serialization formats in the world, so it seems a better solution
is necessary. source_gen does the job but it is not pretty. dart:mirrors are
pretty but have implications in AOT environments. What can we do?
There are at least two possible solutions here.
More declarative replacement for dart:mirrors
The problem with dart:mirrors is that it is imperative and unrestricted in
its capabilities making it very hard to analyze statically. What if Dart
language provided a reflection library which required you to declare statically:
- a set of reflection capabilities that you are going to use;
- a set of classes which you are going to apply those capabilities to.
This might sound to restrictive - but if you think back to our JSON deserialization example if you will realize that:
- we only need to access classes that are marked with
@Entity()annotation; - we need to be able to invoke default constructor of those classes;
- we only need want to iterate their fields, know their types and know how to assign those fields;
A lot of other applications of mirrors are similarly limited: there is an annotation they are looking for and they only perform a certain limited subset of actions over annotated classes.
This observation lead to development of reflectable
package as an experiment. This package is centered around the idea of
declaratively specifying reflection capabilities.
Unfortunately development of reflectable stagnated and it never became part of
the core, which means it has to rely on dreaded transformers to generate
small and fast output on dart2js. Hopefully at some point we will reevaluate
benefits of reflectable and revive it.
Compile time metaprogramming / macro-system
You probably noticed that both source_gen and reflectable approach the
problem from a similar angle: they generate code based on the code you have
written. So it seems that Dart could really benefit from a good macro-system.
This might seem like something from the land of PL dreams because no truly mainstream language sported good macro-system. However I think a lot of developers started to realize that syntax level abstractions are an extremely useful and powerful tool - and language designers are no longer afraid to provide tools that are too powerful. Here are some examples of modern days macro-systems in Scala, Rust and Julia.
For Dart macro-system seemed like impossibility for a very long time, due to a
whole zoo of parsers running around (VM has one written in C++, dart2js
another one written in Dart and dart_analyzer has the third one originally
written in Java and now Dart). However with the recent attempt to unify all
Dart tools behind the same common front-end written in Dart and generating
Kernel it finally
becomes possible to experiment with introducing a macro-system that will be
uniformly supported across all tools from IDE to VM and dart2js compiler.
This is still a dream but a dream that seems well within a grasp.
Want to discuss
contents of this post? Drop me a mail [email protected] or find me on
Mastodon,
X or Bluesky.