Я провел неделю отвечая на вопросы через твиттер аккаунт @jsunderhood. Это краткое резюме недели, самые интересные ее технические моменты.
Вопросы / Ответы
Главное правило оптимизации заключается в том, что оптимизация — это культура. Нельзя год фигачить код лопатой, а потом надеяться исправить все проблемы с производительностью за день. Нет простых магических рецептов, а наемные волшебницы и волшебники, которые могут прилететь в голубых вертолетах и внезапно все исправить, стоят очень много эскимо. Нужно постоянно следить за производительностью, точно так же как вы постоянно прогоняете тесты. Нужно знать базовые алгоритмы и фундаментальные вещи об устройстве платформы, под которую вы разрабатываете. Ну и самое главное - нужно писать вменяемый код.
Q: Как можно посмотреть оптимизированный код в рантайме?
@jsunderhood Как можно посмотреть оптимизированный код в рантайме?
— λ [Roman Liutikov] (@roman01la) 7 апреля 2015Совсем уж в рантайме нельзя (пока?), но можно заставить V8 выплюнуть кое-что на консоль или в отдельные файлы. Для этого у V8 существует ряд флагов:
--trace-hydrogenдоступен даже в любой сборке V8 и позволяет посмотреть высокоуровневое представление (high-level IR), используемое оптимизирующим компилятором;--print-codeи--print-opt-codeдоступны в сборках V8 с включенным дизассемблером и позволяют посмотреть сгенерированный нативный код;
На сегодняшний день проще всего смотреть на все это с помощью IRHydra - это тул, который я написал сам для себя, как раз для того, чтобы было легко изучать, как оптимизируется-деоптимизируется конкретный кусок JS кода. Все инструкции на первой странице, все баги следует слать сюда.
Q: Как устроен оптимизатор в V8.
V8 классический представитель спекулятивного адаптивного мультиуровнего оптимизатора (speculative adaptive multi-tier optimizer). Приблизительная схема выглядит вот так
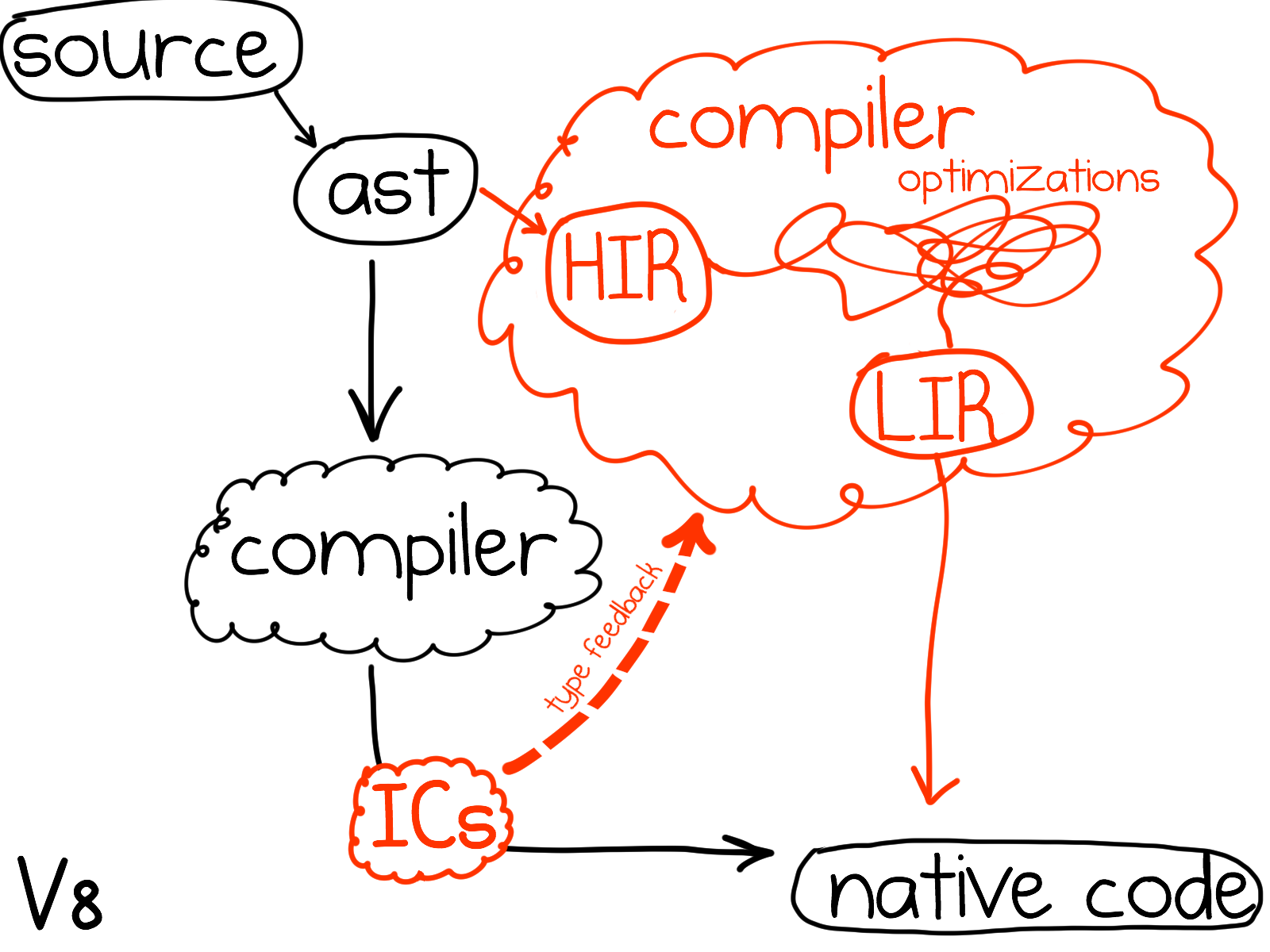
Сначала весь код компилируется быстрым неоптимизирующим компилятором. Причем эта компиляция ленивая - большинство функций компилируются только тогда, когда они вызваны первый раз. Быстрый компилятор ничего не оптимизирует, он просто фарширует генерируемый код встроенными кэшами (inline cache). Эти кэши позволяют даже неоптимизированному коду выполнятся относительно быстро.
Позже, когда V8 замечает, что какая-то функция достаточно горяча, т.е. она была вызвана много раз или содержит цикл(ы), который(ые) делают много итераций - то V8 передает эту функцию оптимизирующем компилятору. Этот компилятор начинает с того, что опрашивает встроенные кэши о том, какие происходило исполнение этой функции и какие типы они видели. На основе этой информации он спекулятивно стоит внутреннее представление (IR) и прогоняет на нем ряд классических и не очень оптимизаций.
Тут важно заметить, что оптимизатор оперирует на уровне отдельно взятой функции, которую ему дали оптимизировать, и большей частью слеп за ее пределами. Выражаясь классическими терминами, этот оптимизатор внутрипроцедурный (intraprocedural), а не межпроцедурный (interprocedural).
Консенсус, кажется, состоит в том, что межпроцедурный анализ для JS вещь слишком затратная по времени и памяти - и сочетание агрессивной открытой подстановки (inlining) и спекулятивных оптимизаций позволяет и так достичь хороших результатов.
Однако, внутрипроцедурность оптимизатора всегда следует иметь ввиду рассуждая о его теоретических возможностях. Так, например, в коде
function g(arr) {
return arr;
}
function f(a, b, c) {
var x = [a, b, c];
g(x);
return x[0];
}Оптимизатор может доказать, что x[0] === a только если x не ускользает (escapes) из его области внимания - т.е. только если он может открыто подставить (inline) g в f и увидеть, что g никак не влияет на содержимое x.
Q: Как и нужно ли прогревать функции вручную?
@jsunderhood насколько возможно и целесообразно заранее "прогревать" JIT для некого кода, который вероятно скоро будет вызван?
— Dmitry Shimkin (@dmitryshimkin) 8 апреля 2015@jsunderhood а нигде не завалялась брошюрка "как совершенно точно прогреть функцию в семь шагов"?
— Zi tri x (@Zitrix8080) 9 апреля 2015На мой взгяд прогрев функция вручную это достаточно сложная и совершенно не целесообразная работа.
Все функции постепенно прогреваются сами по мере использования и оптимизируются на основе их внутреннего поведения. V8 даже способен оптимизировать функции во время их исполнения, посредством техники известной как on stack replacement (OSR), подменяя медленную неоптимизированную версию функции с долгим циклом внутри на оптимизированную версию посреди исполнения этого самого цикла, причем оптимизация будет происходить в отдельном потоке - не мешая самому циклу.
Я могу себе представить случай, когда вы используете V8 на серевере и хотите, чтобы поднимаемый сервер начинал отвечать на запросы с максимальной скоростью с того самого момента, когда вы переведете на него траффик. В этой ситуации можно понять желание прогреть V8 послав на сервер N запросов перед переводом основого траффика… Я, однако, рекомендую делать это только в том случае, если вы понимаете на 100%, что вы делаете и что происходит внутри V8. Иными словами, я не рекомендую этого делать :)
Q: Будущее JS оптимизаций
@jsunderhood тогда как JS стать лучше/быстрее? В чем слабые места современных движков?
— λ [Roman Liutikov] (@roman01la) 6 апреля 2015Этот вопрос не технический и не имеет простого технического ответа, но я решил его включить в дайджест по одной причине: в последующих вопросах/ответах будет сквозить одна и та же тема - современные JS движки достаточно долгое время развивались вглубь уделяя внимания конкретным паттернам программирования, которые либо были уж очень распространены, либо были включены в конкретные широко используемые бенчмарки. Как результат многие вещи остались за бортом прогресса, например, arr.forEach(function (el) { }) может быть заметно медленнее обычного for-цикла, хотя в теории совершенно ясно как свести избыточную стоимость forEach к минимуму. Аналогично с печальной производительностью Function.prototype.bind по сравнению с её рукописными аналогами. Примеры можно приводить бесконечно.
Я считаю в развитии JS движков в настоящий момент наступил тот момент, когда все осознали, что слишком долго копали вглубь - и все постепенно начнут копать в ширину, расширяя зону “быстро исполнимого JS”.
Q: V8 vs. arguments object
@jsunderhood Правду пишут? https://t.co/XPSvqp14uE
— λ [Roman Liutikov] (@roman01la) 9 апреля 2015Да, пишут правду. Если внутри функции неосторожно обращаться с arguments, то Crankshaft откажется эту функцию оптимизировать, потому что он поддерживает только три вида использования arguments.
arguments[i]- взятие аргумента по индексу, причем выход за границы массива аргументов приводит к деоптимизации;arguments.lengthf.apply(x, arguments), гдеf.apply === Function.prototype.apply.
При этом arguments можно сохранять в локальную переменную, но нельзя в этой переменной смешивать с другими значениями. Еще V8 не любит, когда в non-strict функция смешивают именованные параметры и arguments.
function good() {
var a = arguments;
var b = new Array(a.length);
for (var i = 0; i < a.length; i++) b[i] = a[i];
return b;
}
function bad1() {
var a = arguments;
if (!a[0]) a = [1, 2, 3];
}
function bad2() {
return [].call.slice(arguments, 1);
}
function bad3(a) {
return a ? arguments[1] : 42;
}Q: Производительность apply, call, bind
@jsunderhood что по поводу оптимизаций в V8 для apply, bind или call. Раньше видел что call быстрее, потом apply, а потом bind, а сейчас?
— Alex Grand (@GrantedN) 7 апреля 2015Function.prototype.bindсамый медленный из всех - по историческим причинам и плюс его никто не разгоняет. Причем “медленный” относится как к самомуbind, так и к тем функциям, которые он производит. Доходит до абсурдной ситуации, что написанный на коленкте аналогbind, который реализует только часть настоящей семантики, может быть как в десятки раз быстрее. На самом деле этот факт, что можно заменитьbindнаколеночным поделием и не ждать пока все VM разгонят встроенный частично ответственен за то, что встроенный никто и не разгоняет. Действительно - зачем разгонять, если его никто не использует?Function.prorotype.applyна втором месте по скорости. О нем важно знать, чтоfunc.apply(o, arguments)- это один из специальных паттернов, распознаваемых Crankshaft (оптимизирующий комилятор V8), и этот паттерн компилируется в очень эффективный код. Если же вы пытаетесь передатьargumentsв какую-нибудь другую функцию (например, делаете[].slice.call(arguments, 1)), то Crankshaft вообще откажется оптимизировать вашу функцию.Function.prototype.callсамый быстрый из трех. Главное преимуществоcallв том, что ему не нужен временный массив аргументов.func.call(obj, x, y, z)очевидно производит меньше мусора по сравнению сfunc.apply(obj, [x, y, z]). Плюс относительно недавно Petka Antonov присал патч, который научил Crankshaft распознавать вfunc.call(obj, x, y, z)обычный вызов и, например, инлайнить целевую функцию в этом месте.
Q: Try/Catch/Finally vs. V8
@jsunderhood вот здесь https://t.co/PRrbihqVVA для оптимизации предлагают выносить try-catch в отдельную функцию, это правда поможет?
— λ [Roman Liutikov] (@roman01la) 7 апреля 2015Crankshaft не умеет оптимизировать функции содержащие try { } catch (e) { } (и finally). Поэтому если функция горячая, делает много работы и может быть ускорена оптимизациями, которые Crankshaft делает, то такая функция действительно станет быстрее от разбиения её на две - первая, которая делает работу, и вторая, которая ее заворачивает в try/catch
function DoLotsOfComputation() {
for (var i = 0; i < BigNumber; i++) {
// worky-worky
}
}
function DoLostsOfComputationSafe() {
try {
DoLotsOfComputation();
} catch (e) {
// catchy-catchy
}
}TurboFan - оптимизатор, который сейчас находится в разработке и в будущем заменит Crankshaft, умеет оптимизировать функции содержащие try/catch, поэтому через некоторое время этот совет станет неактуальным.
Q: V8 vs. forEach
@jsunderhood реализация forEach внутри отличается от for-loop? Почему бы JIT не инлайнить forEach в for-loop.
— λ [Roman Liutikov] (@roman01la) 7 апреля 2015Array.prototype.forEach в V8 на самом деле написан на обычном JS (self hosted). Проблема в том, что никто пока не научил оптимизатор как удалять всякие избыточные проверки, которым этот forEach нашпигован. По историческим причинам Crankshaft’у даже запрещено инлайнить forEach в вызывающий его код, а это бы очень важный первый шаг, который бы позволил специализировать код forEach под тот массив, на котором его вызывают.
Все вышесказанное применимо ко всем “функциональным” методам на Array.prototype (map, reduce, etc).
Q: defineProperty vs V8
@jsunderhood появились ли какие-то отпимизации в V8, связанные с defineProperty? Почему U*Array (UInt32) не содержит всех методов из Array?
— Alex Grand (@GrantedN) 6 апреля 2015defineProperty как был так и остается очень медленным способом создать свойство на объекте. Однако в последнее время V8 начинает лучше использовать информацию об аттрибутах свойств во время оптимизаций. Так, например, в коде
var Constants = {}
Object.defineProperty(Constants, "AnswerToTheUltimateQuestion", {
value: 42,
// By default:
// writable: false,
// configurable: false
})
function foo() {
return Constants.AnswerToTheUltimateQuestion;
}Если foo будет оптимизированна, то V8 просто подставит 42 вместо Constants.AnswerToTheUltimateQuestion.
Ловушка hidden class transition collision
defineProperty позволяет создавать так называеммые accessor properties и с ними связанна одна ловушка - accessor лучше всего сажать на прототип, а не создавать новый на каждом новом объекте (впрочем, accessor можно без боязни сажать на объект синглтон).
Демка этой проблемы (открыть в IRHydra):
Загадки про производительность
Загадка №1: Map vs. object
начнем утро головоломкой из разряда "и на старуху бывает проруха" http://t.co/Ca3uOLbNL9
— Разработчик (@jsunderhood) 8 апреля 2015Суть этой загадки заключается в следующем: мы генерируем массив случайных строк, заполняем объект и ES6 Map этими строками как ключами, а потом начинаем мерять что быстрее obj[keys[i]] или map.get(keys[i]).
Внезапно оказывается, что obj[keys[i]] заметно быстрее, но только если мы используем keys = Object.keys(obj), вместо оригинальных keys. Упрощенная версия загадки выглядит так:
function randomString() {
var text = "";
var possible = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
var textLength = Math.floor(Math.random() * possible.length);
for( var i=0; i < textLength; i++)
text += possible.charAt(Math.floor(Math.random() * possible.length));
return text;
}
var keys = [];
for (var i = 0; i < 1000; i++) {
keys.push(randomString());
}
var obj = Object.create(null);
var map = new Map();
for (var key of keys) {
obj[key] = key;
map.set(key, key);
}
// 10k ops/sec
for (var i = 0; i < keys.length; i++) obj[keys[i]];
// 19k ops/sec
for (var i = 0; i < keys.length; i++) map.get(keys[i]);
var objectKeys = Object.keys(obj);
// 10k ops/sec
for (var i = 0; i < keys.length; i++) map.get(objectKeys[i]);
// 100k ops/sec
for (var i = 0; i < keys.length; i++) obj[objectKeys[i]];Казалось бы содержимое objectKeys точно такое же как keys, как obj[keys[i]] может быть быстрее obj[objectKeys[i]]?
Отгадка состоит в том, что быстрый путь (fast path) операции obj[k] поддерживает только интернализованные строки, а V8 интернализует только некоторые строки (например, строковые литералы или имена свойств), и не интернализует результат конкатенации. Иными словами строки в массиве keys не интернализованные, а строки с массиве objectKeys, хоть и равны строкам из keys по содержанию - интернализованные, потому что это имена свойств obj.
Определяющее свойство интернализованных строк состоит в том, что две интернализованные строки могут быть сравнены простым сравнением указателей. Сравнение других строковых представлений (при совпадении длин и хэшей) требует сравнения их содержимого. Именно поэтому быстрый путь операции obj[k] для объектов со словарным представлением хранилища свойств и поддерживает исключительно интернализованные ключи k, все остальные ключи обрабатываются общим кодом внутри среды исполнения, который гораздо медленнее этого fast path.
Шпаргалка: представления строк в V8.
Любая строка в V8 состоит из трех фиксированных полей тип, хэш, длина и содержимого, представление которого зависит от конкретного типа строки.
+-------+ | | type descriptor (aka map) +-------+ | | hash +-------+ | | length +-------+ | +-+ | | | ~~~~~~~~~ > payload | | | | +-+ +-------+
Плоские строки (sequential, flat) просто содержат в себе все свои символы:
+-------+ | | +-------+ | | +-------+ | | +-------+ | xxxx +-+ | xxxx | | ~~~~~~~~~ > characters | xxxx | | | xxxx +-+ +-------+
Cons-строки используются для представления результатов конкатенации без реального копирования содержимого конкатенируемых строк. Например, A + B будет представлена как
+-------+ | | +-------+ | | +-------+ | | +-------+ | *---+---> string A +-------+ | *---+---> string B +-------+
Фактически это аналог структуры данных rope.
Sliced-строки используются для представления результатов операции взятия подстроки без реального копирования символов. Например, A.substring(1) может быть представлена так:
+-------+ | | +-------+ | | +-------+ | | +-------+ | *---+---> string A +-------+ | 1 | offset within A +-------+
Еще есть так называемые внешние строки, существующие для экономии памяти при встраивании V8 в другие проекты (например, чтобы не хранить одну и ту же строку два раза - и в внутри DOM реализации на C++ и внутри V8):
+-------+ | | +-------+ | | +-------+ | | +-------+ | *---+---> v8::String::ExternalStringResource (C++) +-------+
V8 отслеживает какие символы используются внутри строки и выбирает однобайтовое (Latin1) или двух-байтовое (UTF16) представление строки автоматически для экономии памяти.
Плоские и внешние строки так же разделяются на интернализованные и неинтернализованные. Интернализация это фактически поиск равное строки в глобальной таблице интернализованных строк и добавление в нее, если строка не найдена.
Загадка №2: на Stack Oveflow
Want to discuss
contents of this post? Drop me a mail [email protected] or find me on
Mastodon,
X or Bluesky.