Disclaimer: This is my personal blog. The views expressed on this page are mine alone and not those of my employer.
Every time I stumble upon yet another cross language benchmark comparison I remember Fight Club. No, seriously! What can be more enjoyable than watching your favorite language pummel not-so-favorite languages? Developers love cross language benchmark games. There is no doubt about that. But they tend to forget the first rule of benchmark club:
The first rule of benchmark club is you do not talk about benchmark club jump to conclusions.
A couple of weeks ago one of my friends sent me a link to Programming Language Benchmarks by Attractive Chaos, a younger brother of The Computer Language Benchmarks Game maintained by Isaac Gouy, and asked for some insight into V8's performance on matmul_v1.js benchmark.
So I cloned official PLB repo, slightly patched matmul_v1.js to make it work with V8's shell instead of d8 (which I do not use) and started digging.
% svn info $V8 | grep Revision Revision: 7810 % time $V8/shell matmul_v1.js -95.58358333329998 $V8/shell matmul_v1.js 11.16s user 0.15s system 100% cpu 11.264 total
(measurements for this post were done on V8 r7810 so results are slightly different from the ones for r7677 shown in PLB table)
Yikes. 11s are not very exciting especially when PyPy and LuaJIT2 show 8.5s and 2.7s respectively.
Foes of number representation
The only number type JavaScript and Lua provide is double precision floating point and requires 64 bits of memory. Thus VM implementers have a choice either to make every slot (local variables, objects properties, array elements) wide enough to contain a 64-bit double or to store 64-doubles as boxed values.
V8 goes with the latter approach and boxes† every number that does not fit into 31-bit integer range. Here is for example a backing store of an array [3.14, 1, 2.71, 2] on 32-bit architecture:
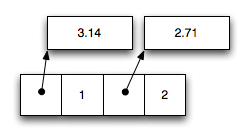
LuaJIT2 (as well as JSC and SpiderMonkey) on the other side uses a technique called NaN-tagging, which allows to store both pointers (or other 32-bit values) and doubles in 64-bit wide slots. Here is how the same array will look like in these VMs:

V8's approach allows to save heap space when numbers mostly fit into 31-bit integer range but it also incurs overhead of double indirection and extra allocation when application starts working with dense arrays of floating point numbers. Fortunately there is a solution: WebGL typed arrays.
† - It should be noted here that V8's optimizing backend is able to keep local double values and temporaries on the stack and in xmm registers. Boxing only occurs when the value escapes optimized code (e.g. is stored to a property, passed as an arguments or returned from a function). Non-optimized code always works with boxed numbers. ↑
Float64Array
Typed array constructed with new Float64Array(N) behaves just like a normal JS object almost in every aspect:
% $V8/shell V8 version 3.3.5 (candidate) > arr = new Float64Array(10) [object Object] > arr.prop = "this is prop"; this is prop > Object.keys(arr) 0,1,2,3,4,5,6,7,8,9,length,BYTES_PER_ELEMENT,prop > arr.prop this is prop
The only observable difference is in semantics of indexed properties. This specialized semantics allows V8 to use unboxed backing stores for such typed arrays.
Will it be cheating to use such specialized data type? I do not think so. We are trying to get some real world data and educate programmers about strength and weaknesses of a particular VM. Nobody uses std::list<std::list<double> > to represent dense matrices in C++. The same applies to all participating languages. For example PyPy's version of matmul benchmark matmul_v2.py uses module array, which provides Python's equivalent of typed arrays. Mike Pall contributed matmul_v2.lua that relies on a low-level FFI type which is not even safe unlike it's Python and JavaScript counterparts:
% ./luajit-2.0/src/luajit LuaJIT 2.0.0-beta6 -- Copyright (C) 2005-2011 Mike Pall. http://luajit.org/ JIT: ON CMOV SSE2 SSE3 SSE4.1 fold cse dce fwd dse narrow loop abc fuse > ffi = require 'ffi' > arr = ffi.new 'double[10]' > for i = 0, 10000 do arr[i] = 0 end zsh: bus error ./luajit-2.0/src/luajit
So here is matmul_v2.js a slightly altered version of matmul_v1.js that uses Float64Arrays to store matrix rows. Some would probably notice that I did not even bother to manually hoist row's loads like somebody did for matmul_v1.js, because V8's optimizing backend is able to perform loop invariant code motion in this case.
% time $V8/shell matmul_v2.js -95.58358333329998 $V8/shell matmul_v2.js 2.61s user 0.07s system 101% cpu 2.650 total
Using the right representation, as you can see, gives a nice 4.2x speedup which puts V8 pretty close to LuaJIT2 and low-level statically typed languages like C.
But LuaJIT2 is still faster! Why?
Indeed. LuaJIT2 is still faster.
% time $LUAJIT/luajit matmul_v1.lua 1000 -95.5835833333 $LUAJIT/luajit matmul_v1.lua 1000 2.26s user 0.05s system 99% cpu 2.325 total
There are two main reasons:
- V8 is missing array bounds check elimination. LuaJIT2 is able to hoist bounds checks out of the hot loop, V8 does not try to do that.
- V8 has termination and debugging API while LuaJIT2 does not. For example any script on the webpage can be interrupted from Chrome DevTools by the pause button. To support these APIs V8 has to insert an interruption check on the backedge of every loop.
When did you have to multiply two matrices last time?
Most of programmers don't have to deal with matrix multiplication, signal processing and DNA sequencing every day, but it's easy to forget about that when interpreting results of cross language benchmark games, especially if your favorite language implementation is da winner.
But it's really dangerous to base your language choice on such comparisons as they are pretty much one sided (tight numeric loops) and do not cover all important facets of a language implementation.
Out of curiosity I've rewritten DeltaBlue, constraint solver written in a classical object-oriented style, included into V8 Benchmark Suite from JavaScript into Lua.
When porting benchmark's code from JavaScript to Lua I've used metatables to implement object hierarchy. This approach is widespread in Lua community and is described in the book written by language authors. DeltaBlue does not use any weird JavaScript features so rewrite was very smooth and mostly done by Emacs's "Replace Regexp" :-) I've used Lua for 5 years so I am also pretty sure that result is as close to idiomatic Lua as possible. Original benchmark uses global namespace, which is considered bad taste in Lua, so I created two Lua versions: one directly converted from JavaScript (global variables became global variables) and one with all global variables turned into local variables.
Surprisingly LuaJIT2 does not perform very well on this benchmark:
% time $LUAJIT/luajit deltablue-10000iterations.lua globals $LUAJIT/luajit deltablue-10000iterations.lua globals 55.03s user 0.09s system 99% cpu 55.630 total
% time $LUAJIT/luajit deltablue-10000iterations.lua locals $LUAJIT/luajit deltablue-10000iterations.lua locals 26.72s user 0.04s system 99% cpu 26.824 total
% time $V8/shell deltablue-10000iterations.js $V8/shell deltablue-10000iterations.js 4.64s user 0.04s system 89% cpu 5.213 total
As you can see V8 is roughly 5-12x times faster. Does it mean that LuaJIT2 is a worse compiler? Definitely not. It's probably just not tuned for this kind of workload. (There is also a slight possibility that I screwed somewhere when doing search&replace operations).
Conclusion
Everything has it's own strength and weaknesses. VMs, compilers and even benchmark suites. There is no simple answer when the question is "which language is better?". Even more: to compare two languages you need to be adept in both.
In the beginning of this post I've mentioned the first rule of benchmark club and I think it's appropriate to conclude by reminding you about the second rule.
The second rule of benchmark club is you DO NOT jump to conclusions.
Want to discuss
contents of this post? Drop me a mail [email protected] or find me on
Mastodon,
X or Bluesky.